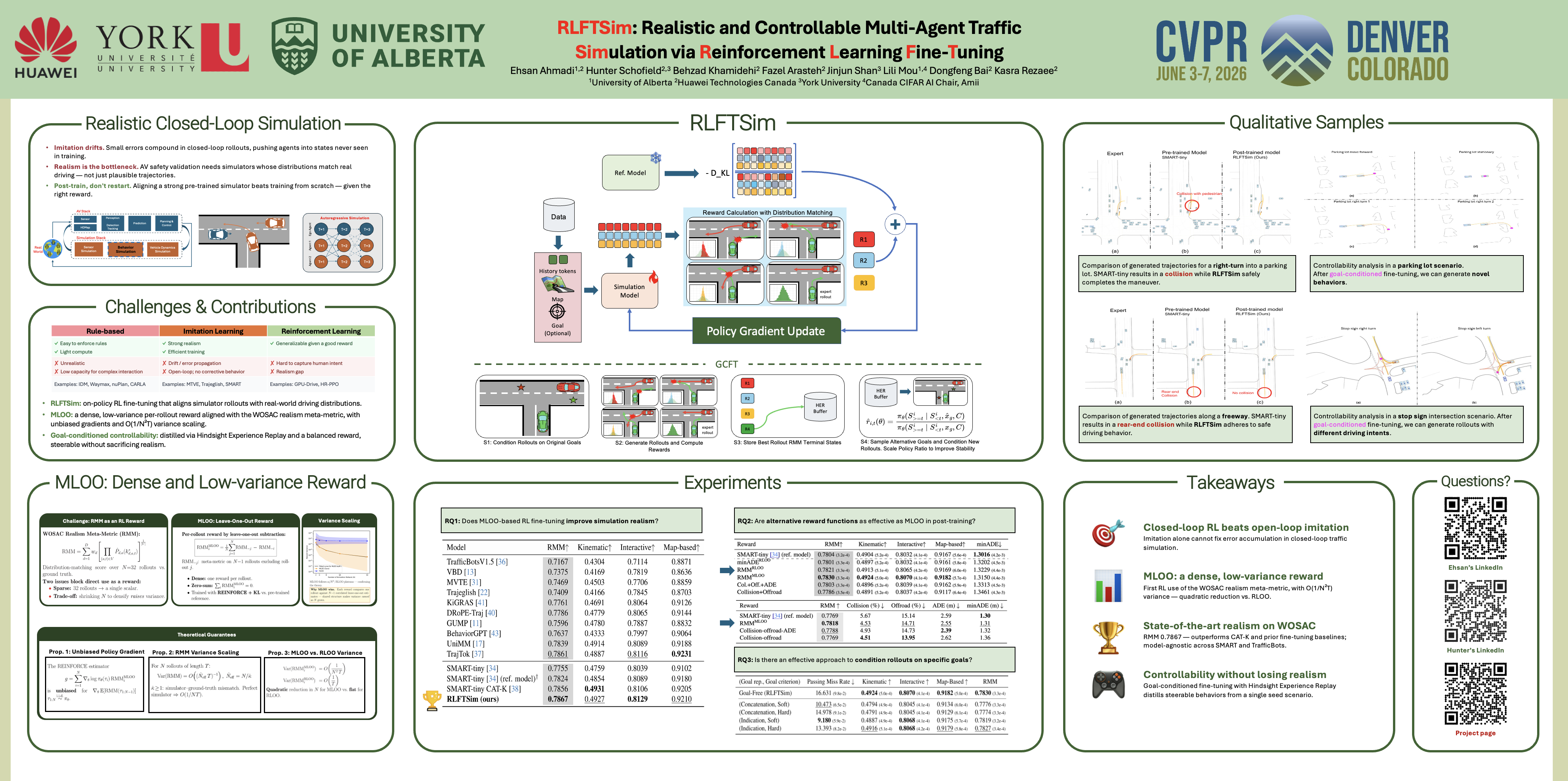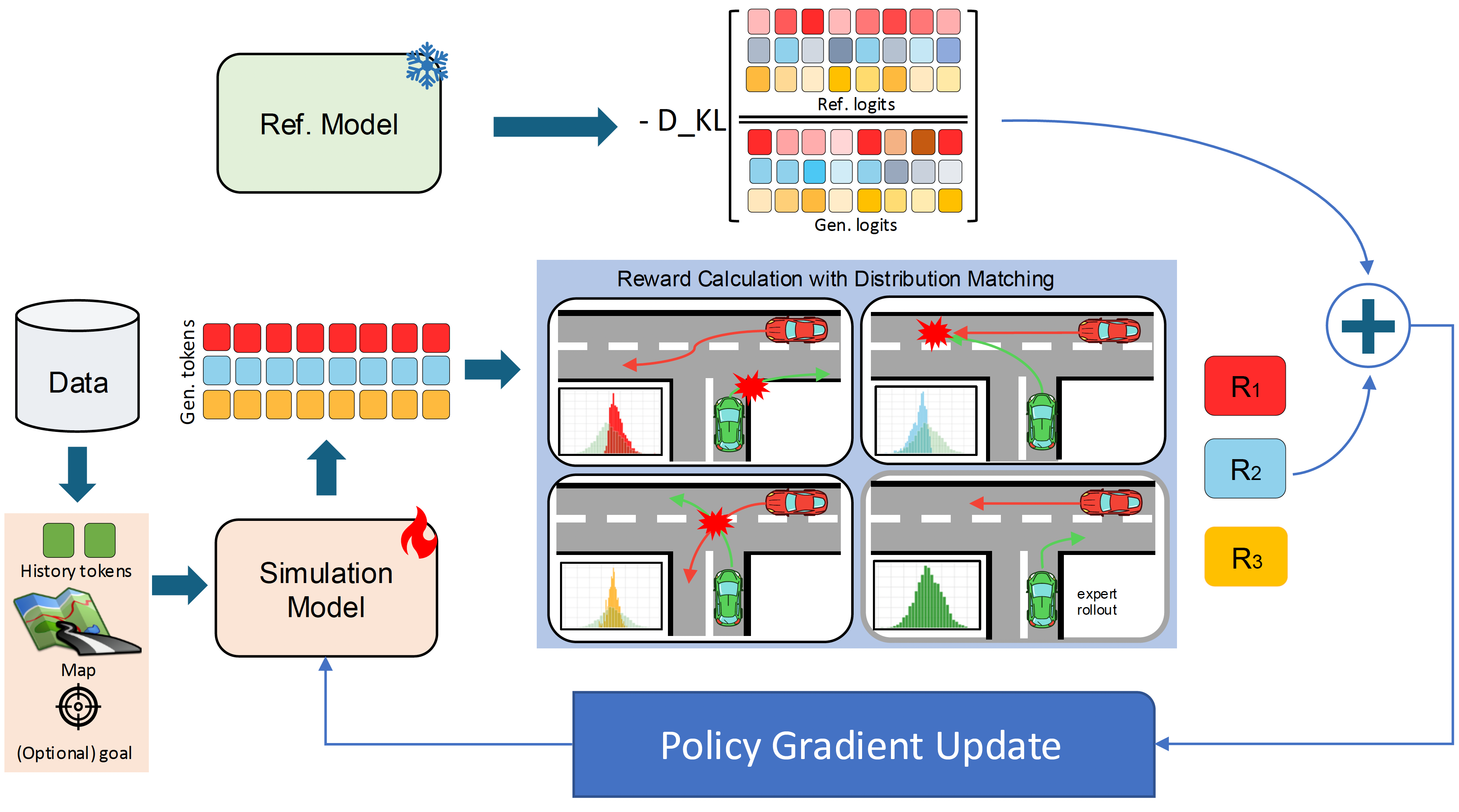
RLFTSim post-training pipeline. We fine-tune a pre-trained simulator with closed-loop, on-policy RL to match the real-world distribution across kinematic, interactive, and map-based features. Our key contribution is MLOO, a dense, low-variance, per-rollout reward built from a leave-one-out construction over the realism meta-metric — making fine-tuning sample-efficient and stable. An optional goal input with a goal-attainment reward further distills controllability without sacrificing realism.
Supervised open-loop training has been widely adopted for training traffic simulation models; however, it fails to capture the inherently dynamic, multi-agent interactions common in complex driving scenarios. We introduce RLFTSim, a reinforcement-learning-based fine-tuning framework that enhances scenario realism by aligning simulator rollouts with real-world data distributions and provides a method for distilling goal-conditioned controllability in scenario generation. We instantiate RLFTSim on top of a pre-trained simulation model, design a reward that balances fidelity and controllability, and perform comprehensive experiments on the Waymo Open Motion Dataset. Our results show improvements in realism, achieving state-of-the-art performance. Compared with other heuristic search-based fine-tuning methods, RLFTSim requires significantly fewer samples due to a proposed low-variance and dense reward signal, and it directly addresses the realism alignment issue by design. We also demonstrate the effectiveness of our approach for distilling traffic simulation controllability through goal conditioning.
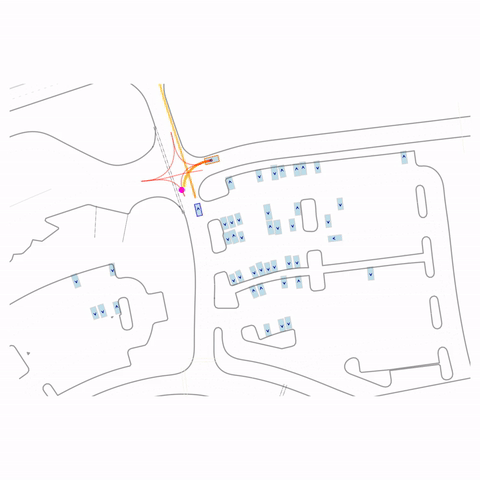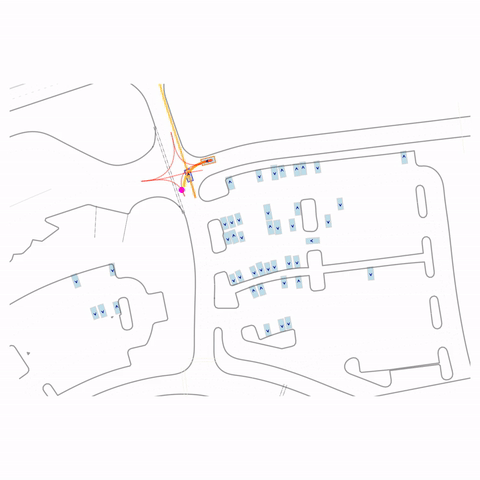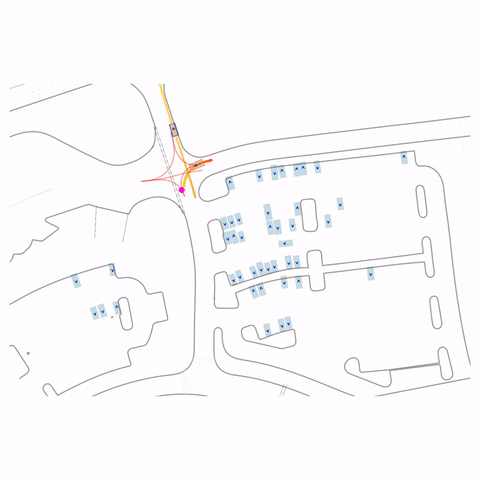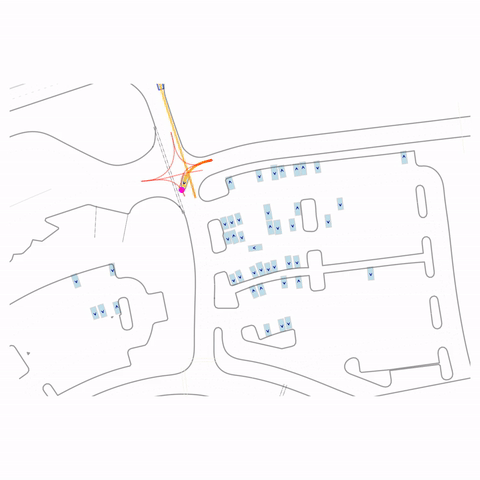
Side-by-side comparison of the base model (pre-train) and RLFTSim (post-train) on challenging traffic scenarios.
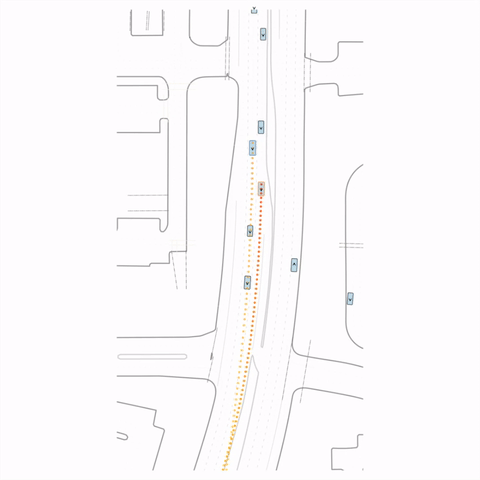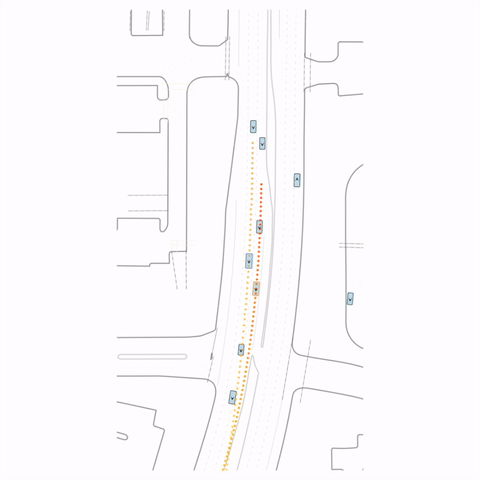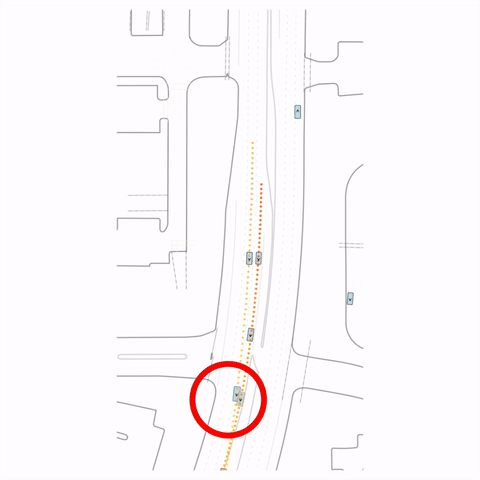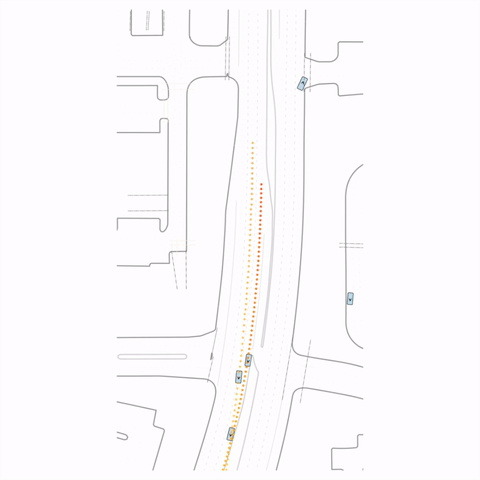
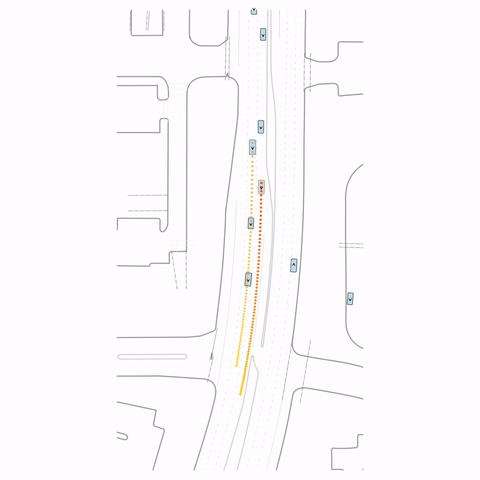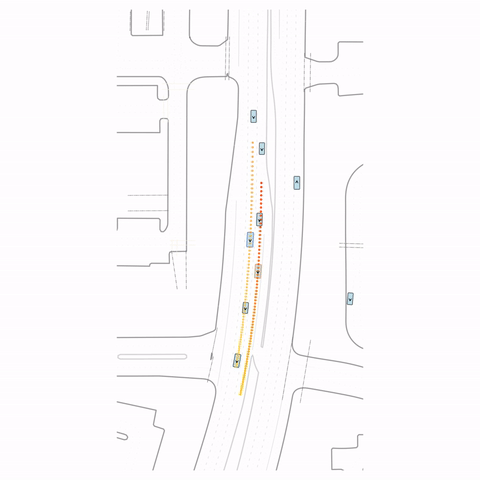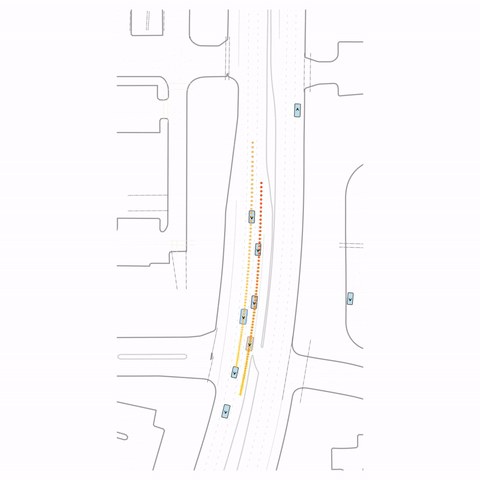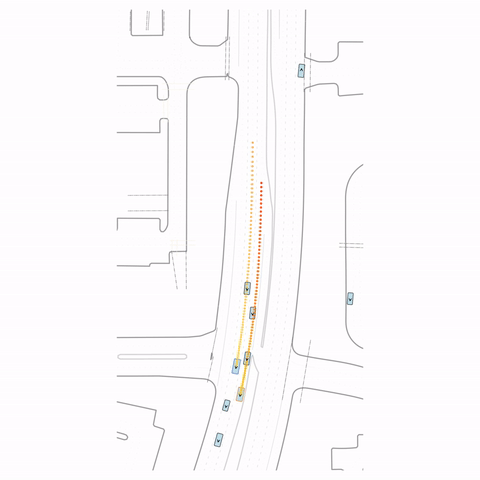
Figure 1 — Collision & Off-road: The pre-trained model generates unrealistic off-road behavior and a collision with cross-traffic, while the post-trained model (RLFTSim) produces realistic lane-following behavior that respects traffic rules.
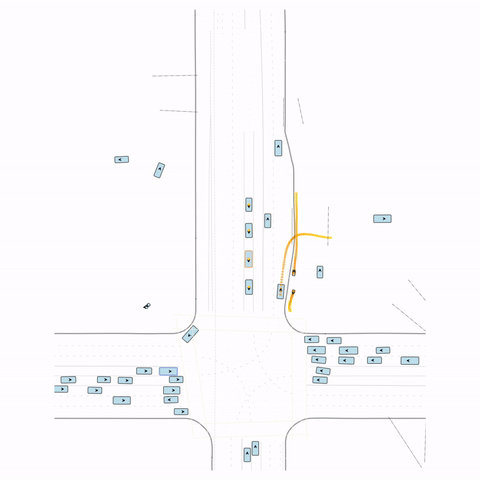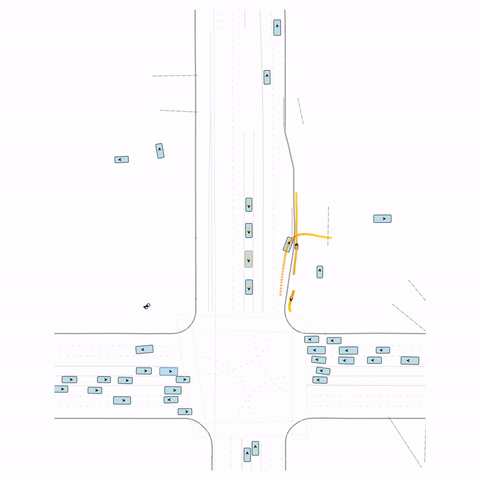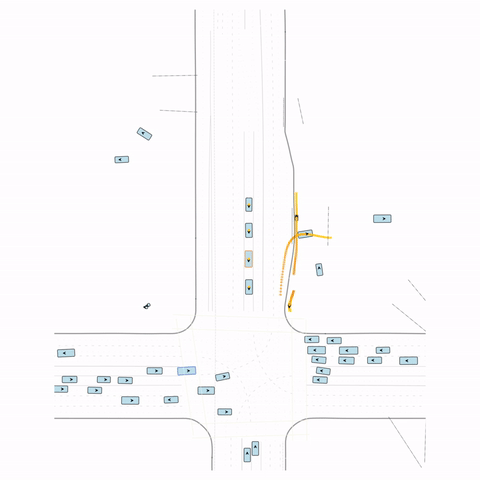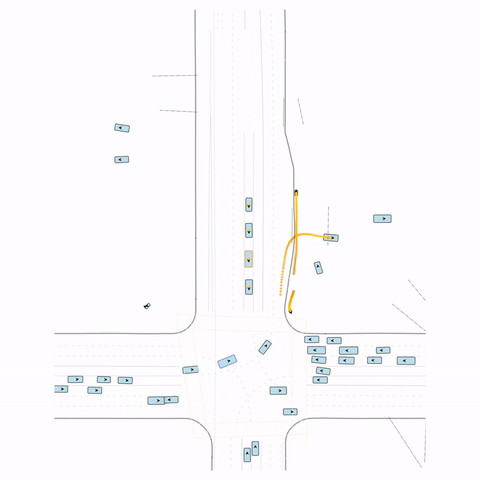
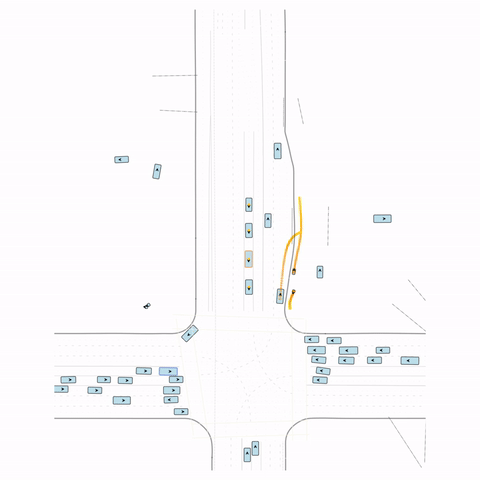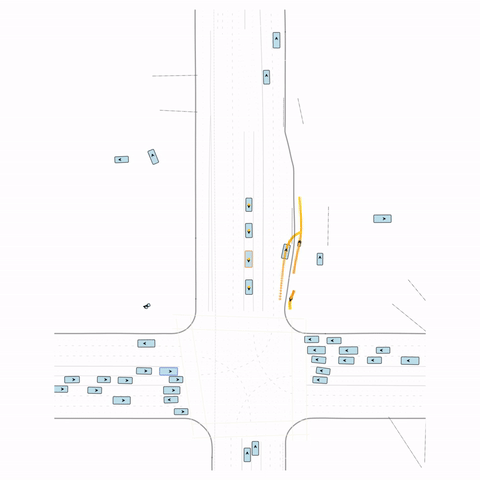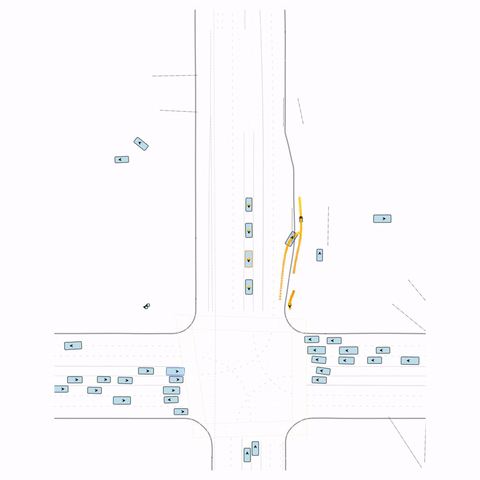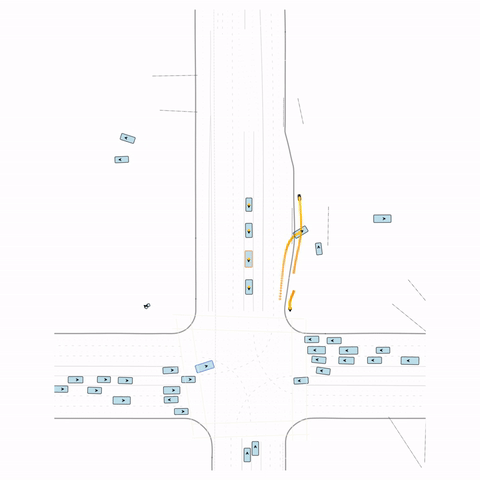
Figure S1 — Collision 1: In the pre-trained model, the vehicle entering the circle fails to yield to the pedestrian and collides with it. In the post-trained model, the vehicle yields to the pedestrian.
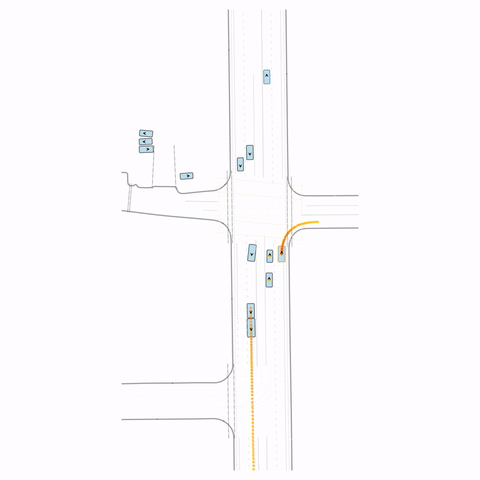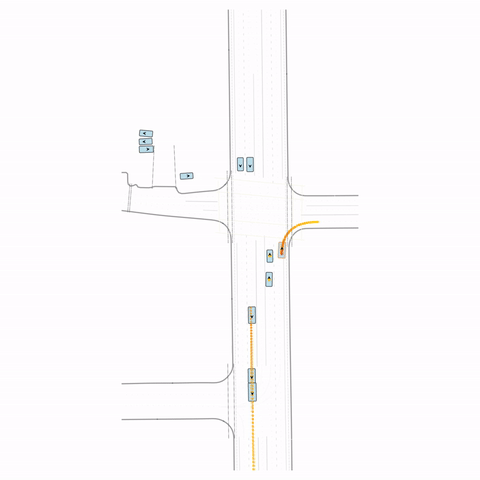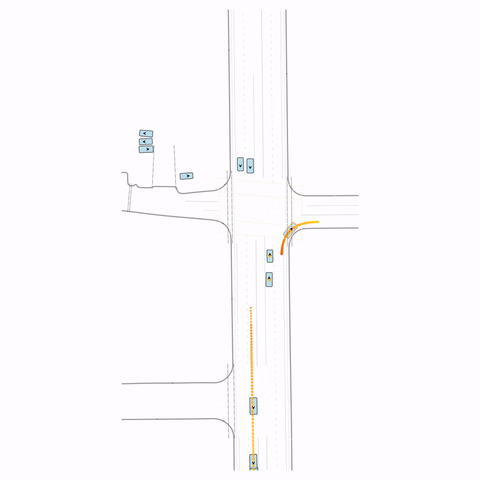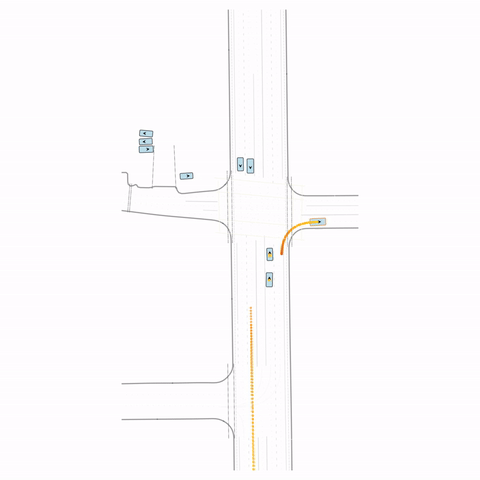
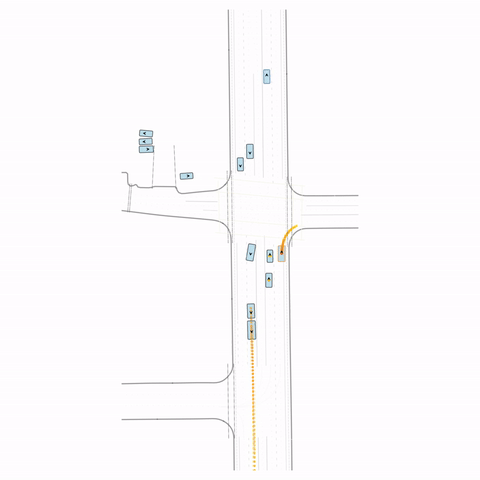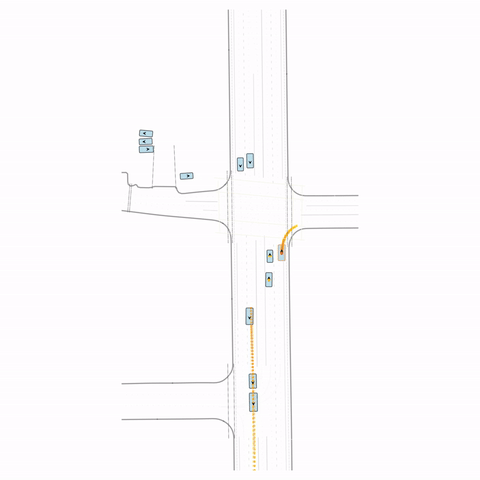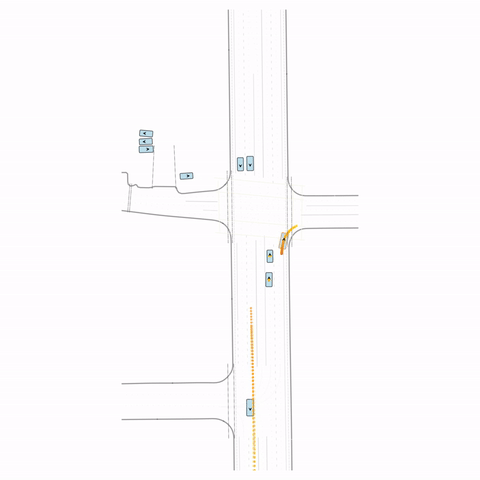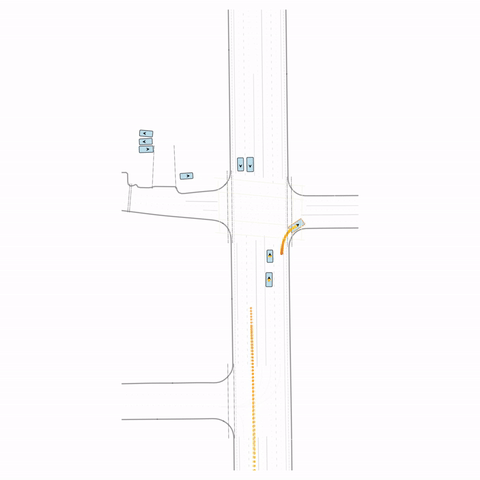
Figure S2 — Collision 2: The pre-trained model produces a rear-end collision between two vehicles at the bottom of the scene. The post-trained model avoids this accident.
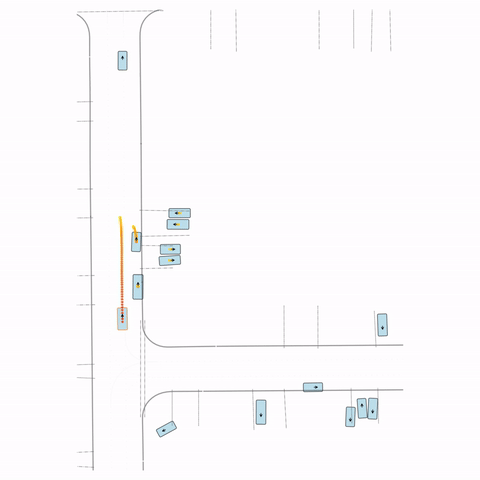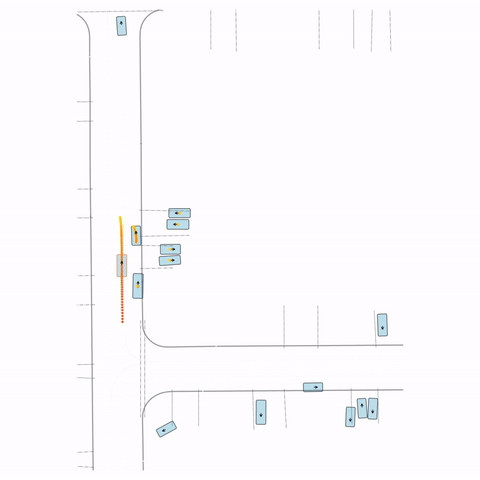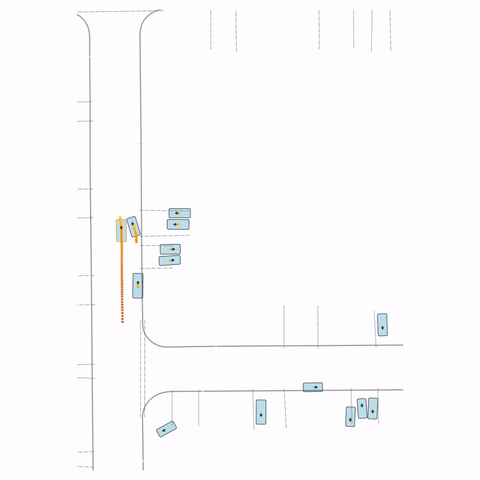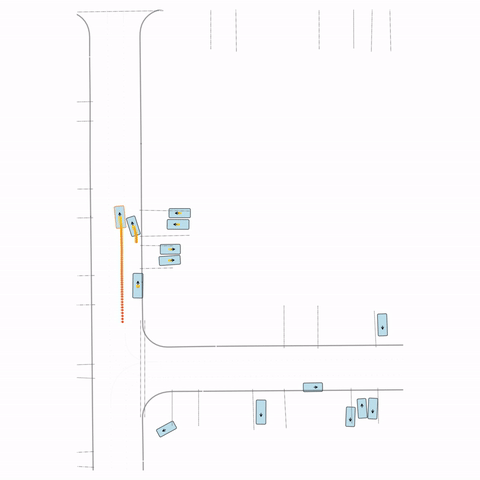
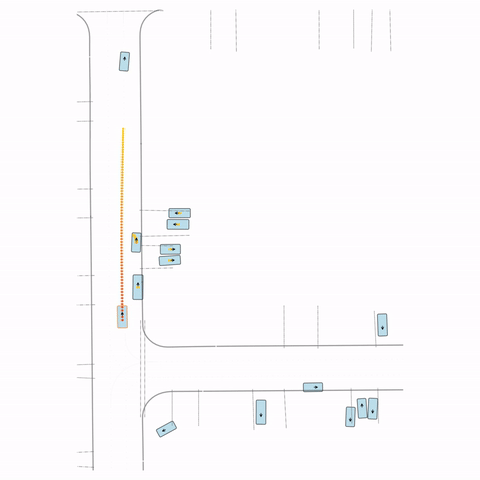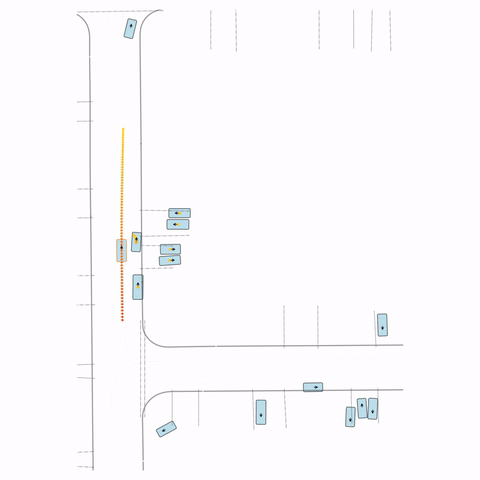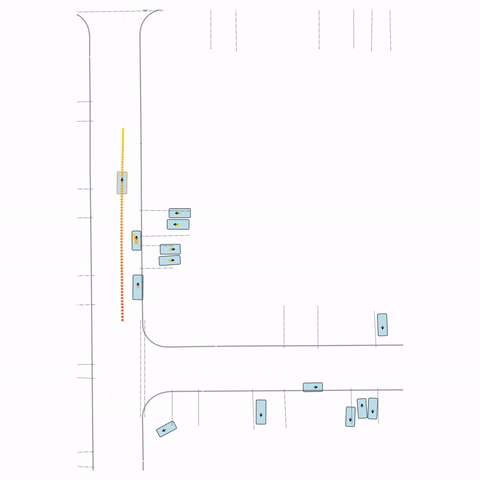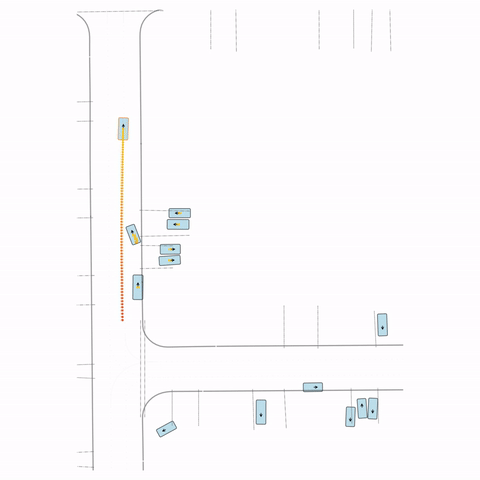
Figure S3 — Collision 3: The pre-trained model's parked vehicle attempts to enter the road, colliding with a passing vehicle. The post-trained model waits for the road to clear before entering.
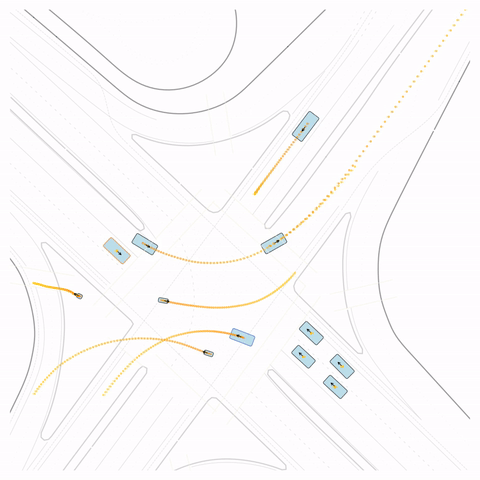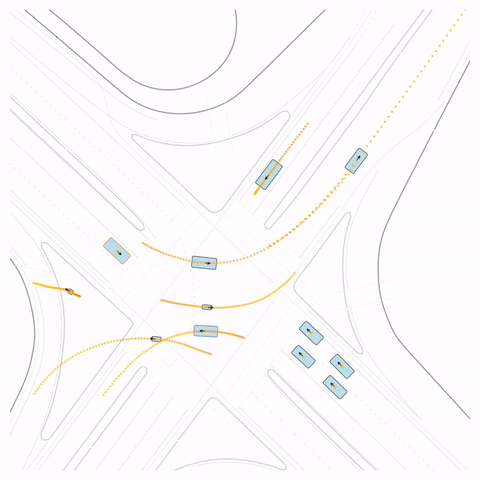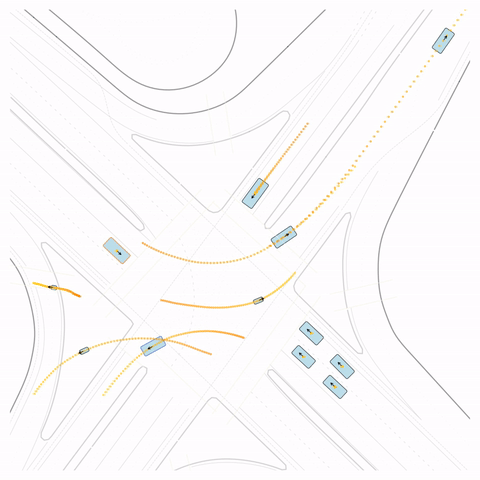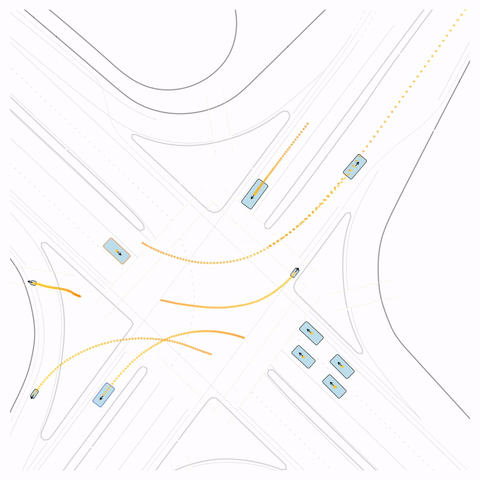
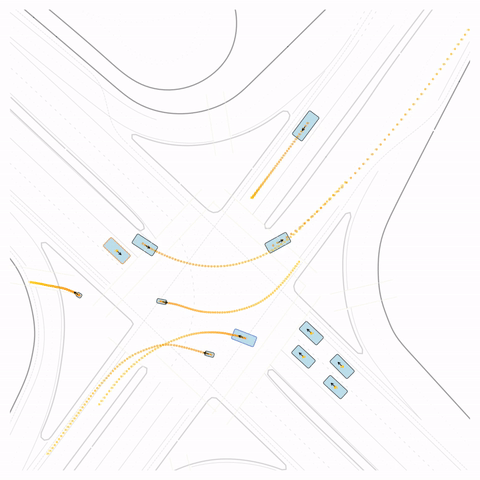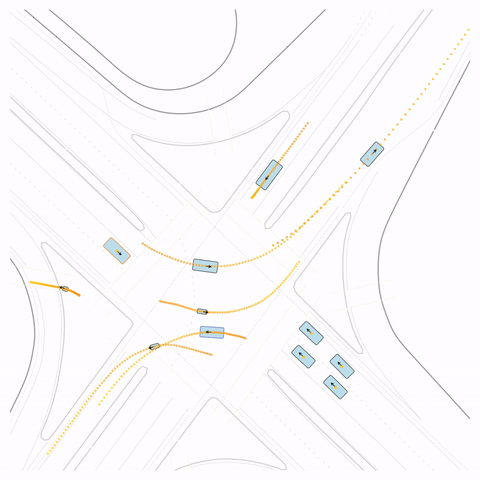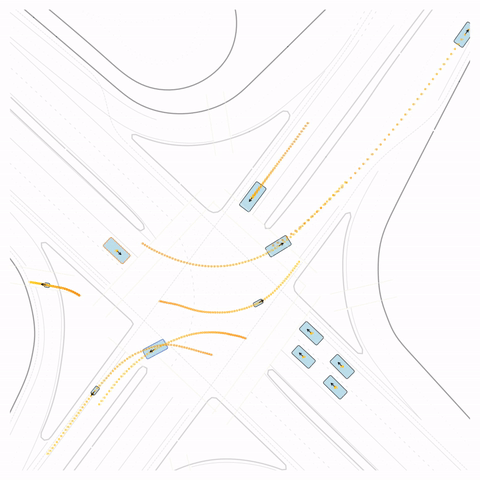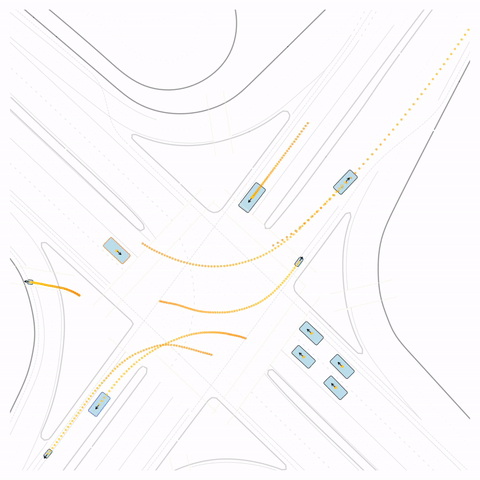
Figure S4 — Off-road: The pre-trained model's cyclist goes off-road. The post-trained model (RLFTSim) adheres to the drivable area.
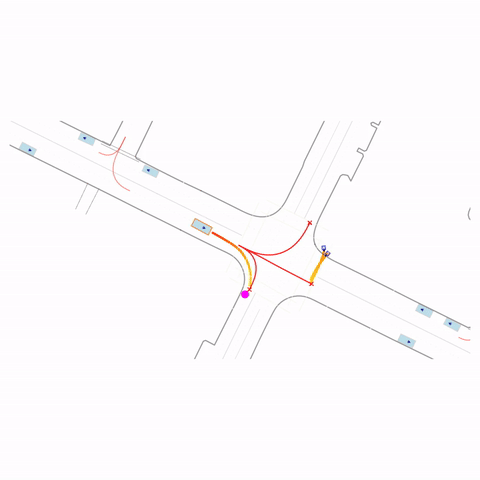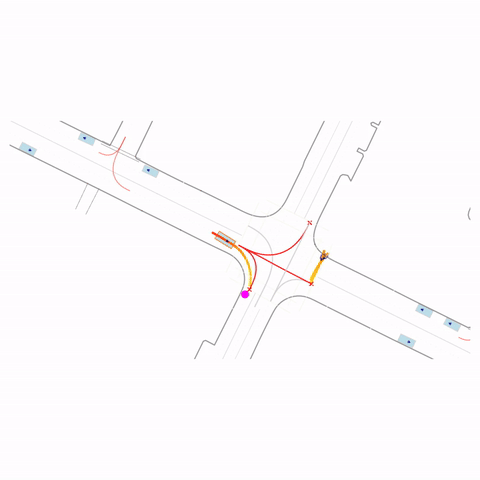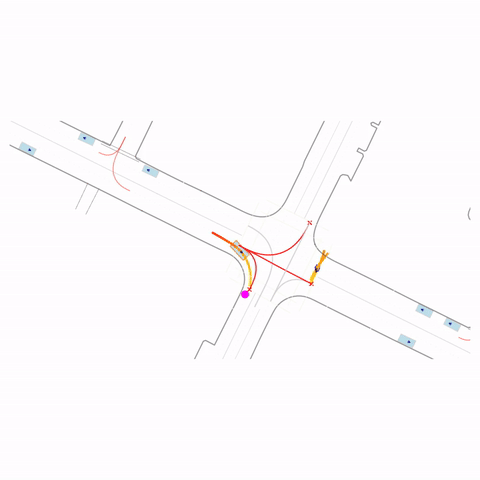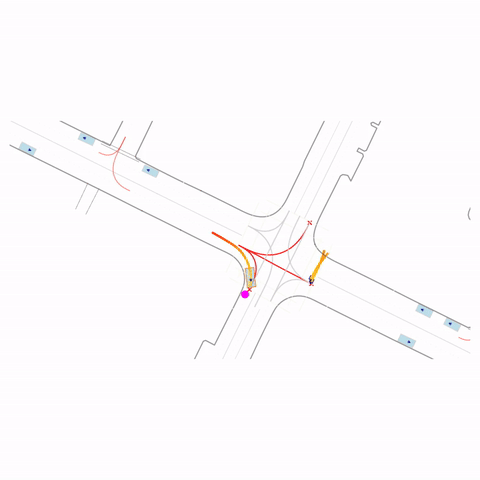
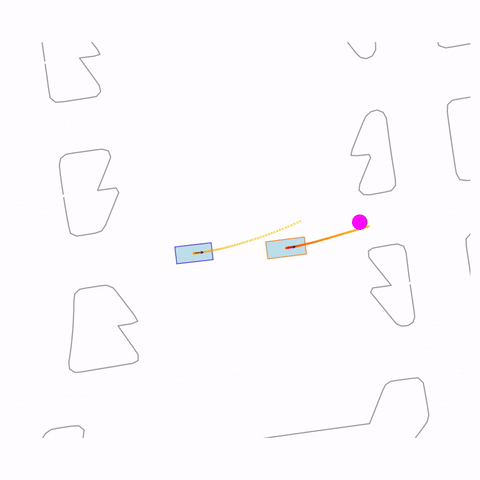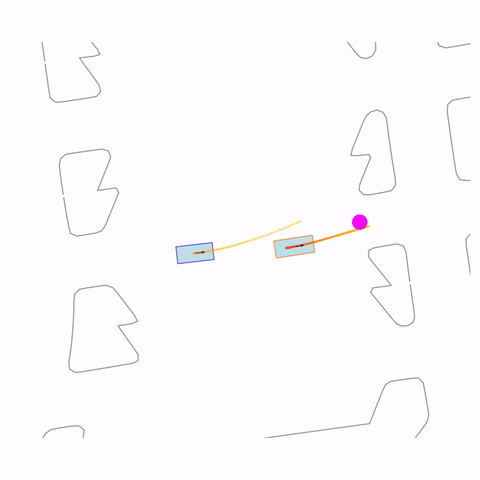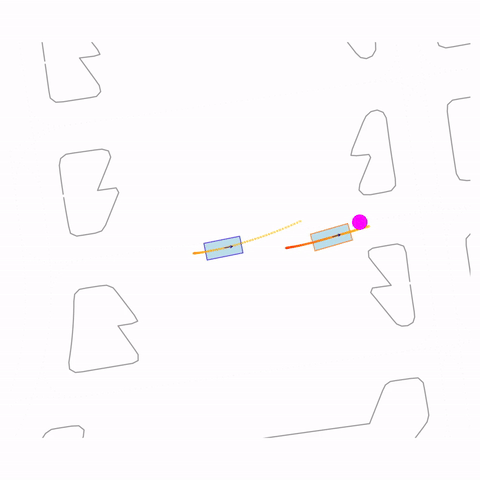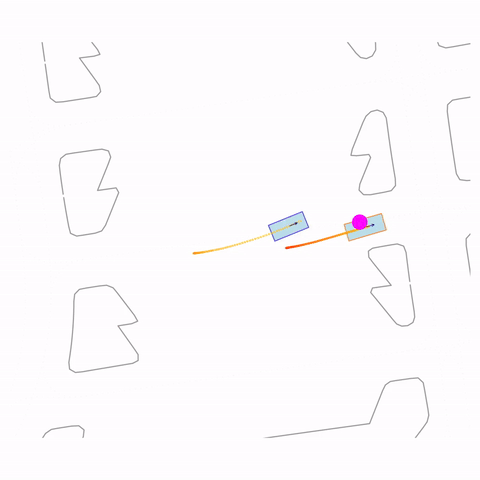
Controllability via goal-conditioning. The goal point is shown as a magenta circle. We compare various goal representations.
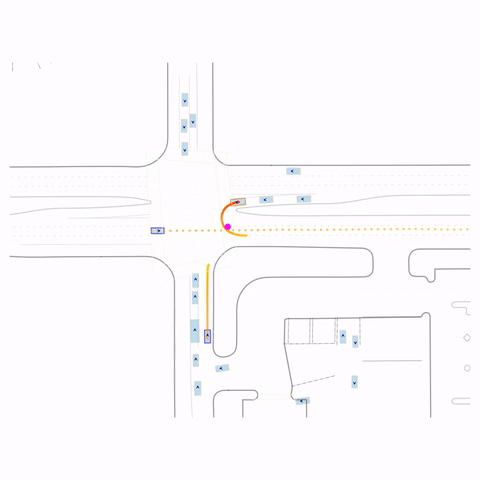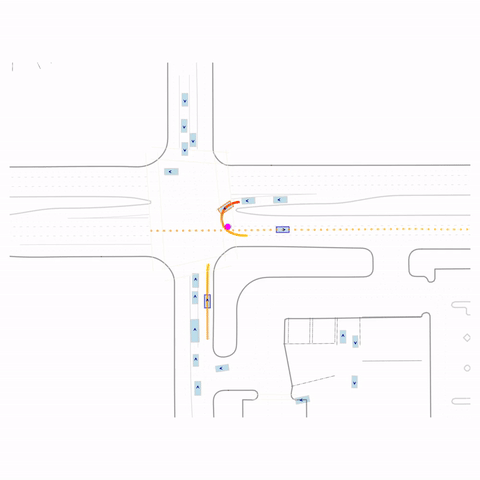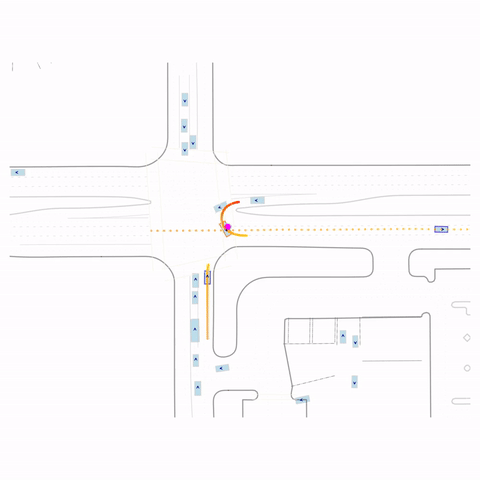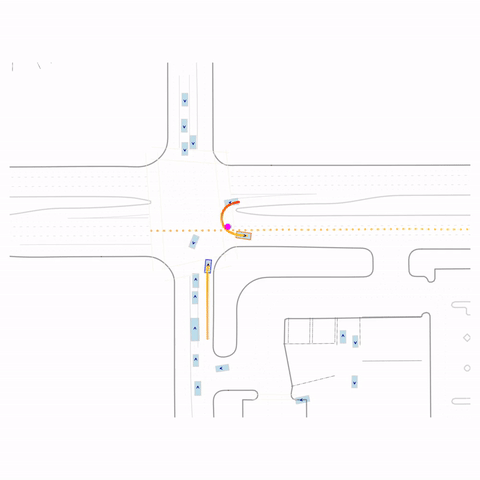
Successful U-Turn
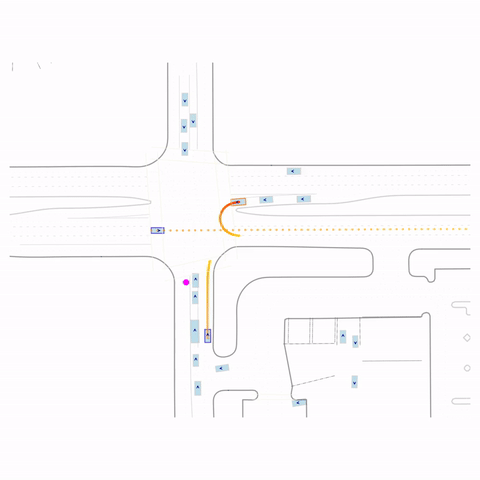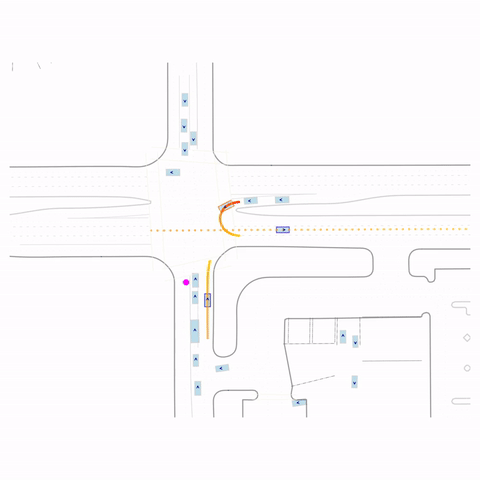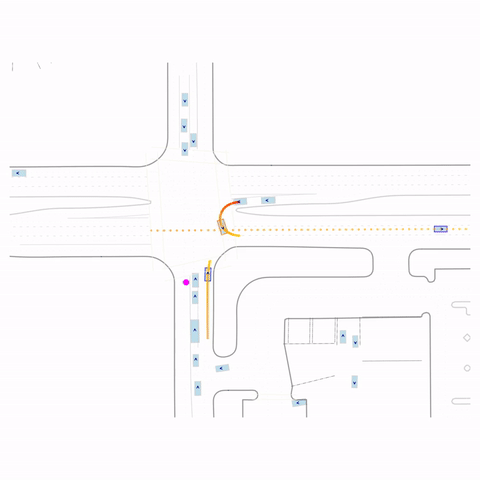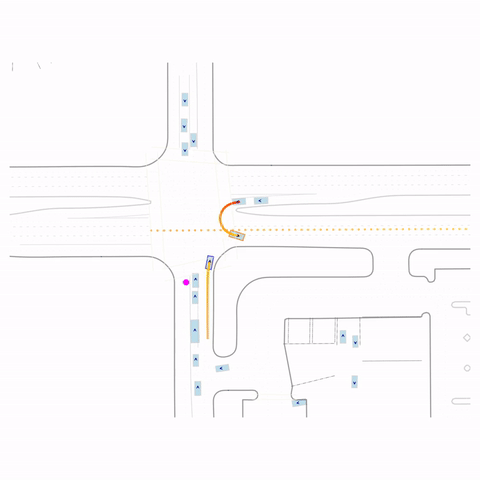
Failed Left Turn
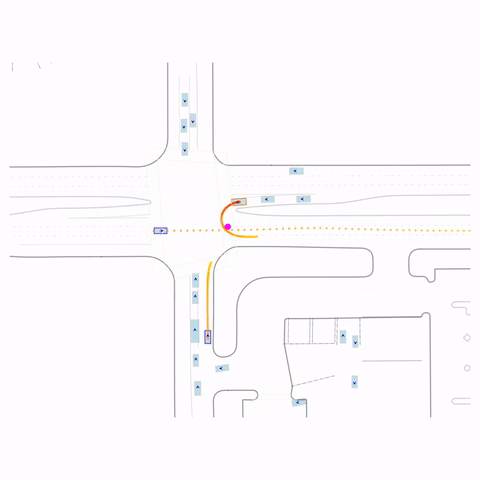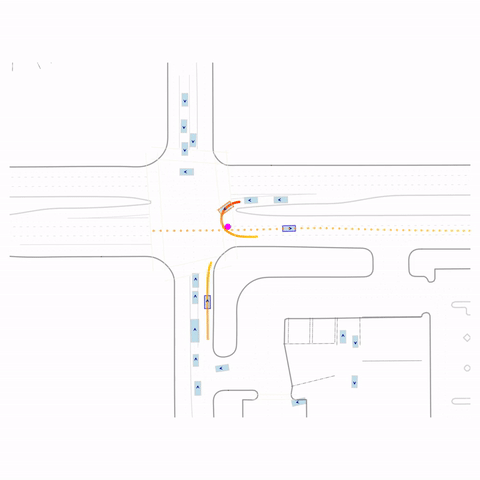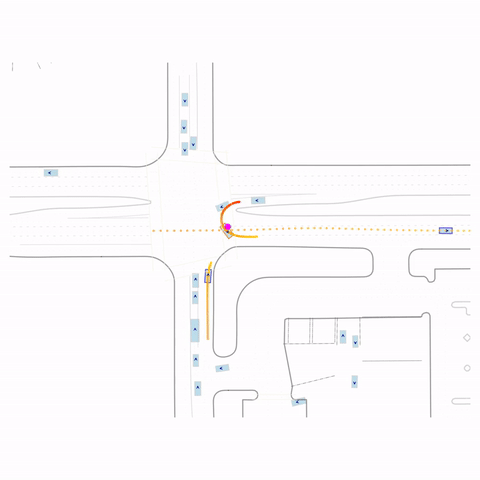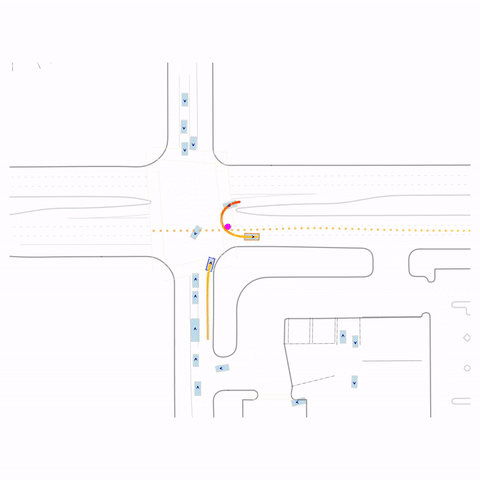
Successful U-Turn
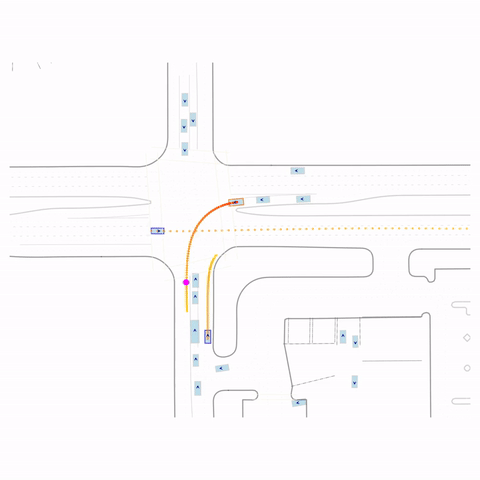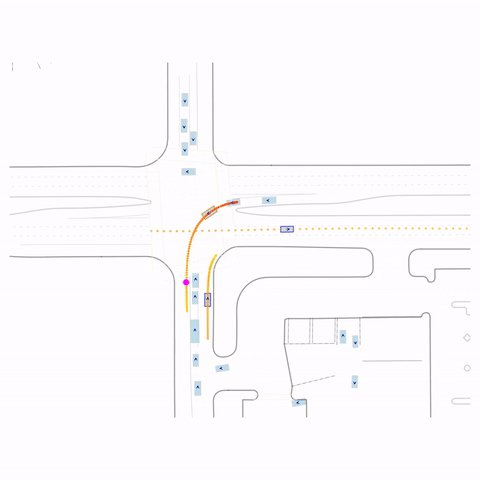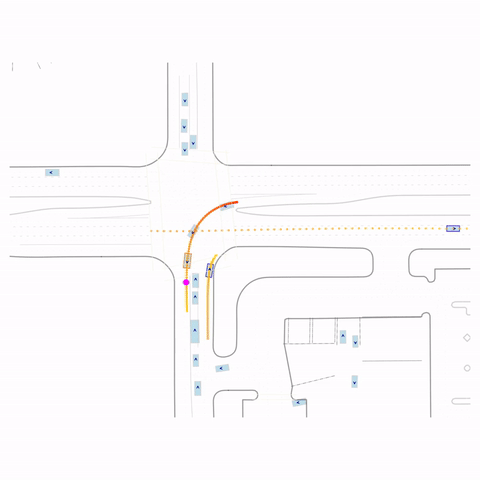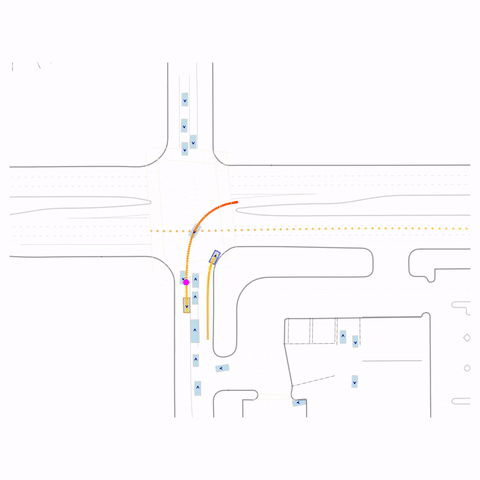
Successful Left Turn
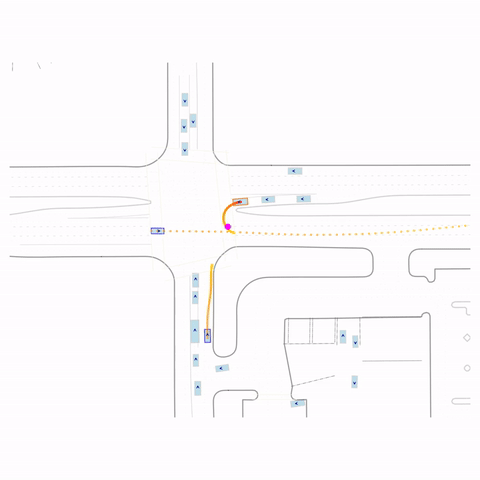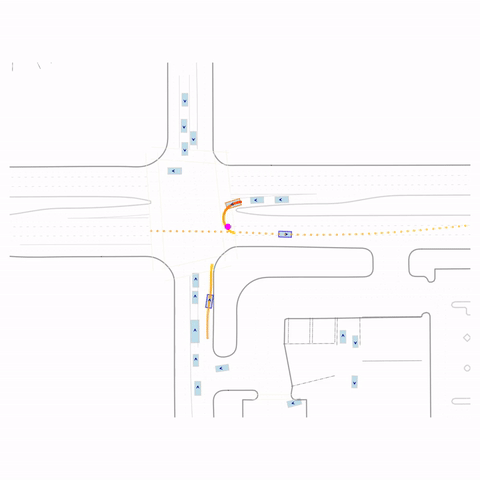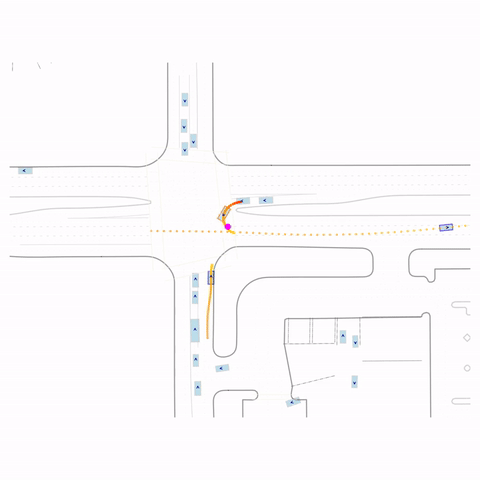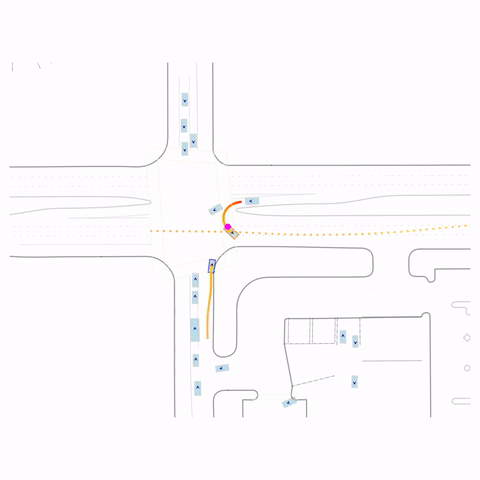
Successful U-Turn
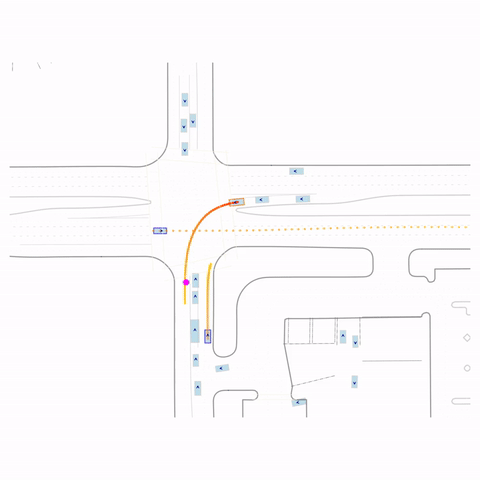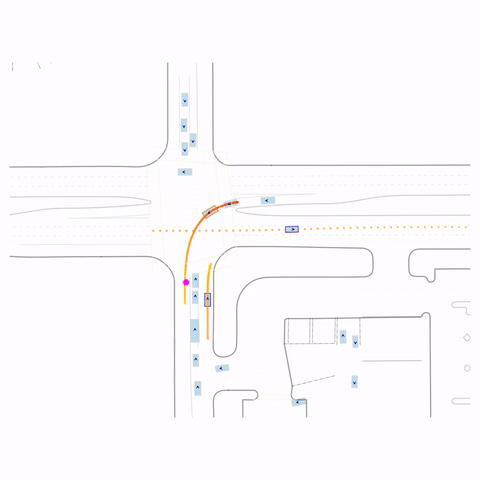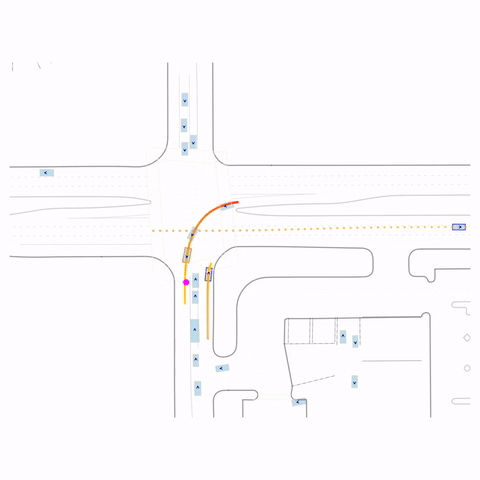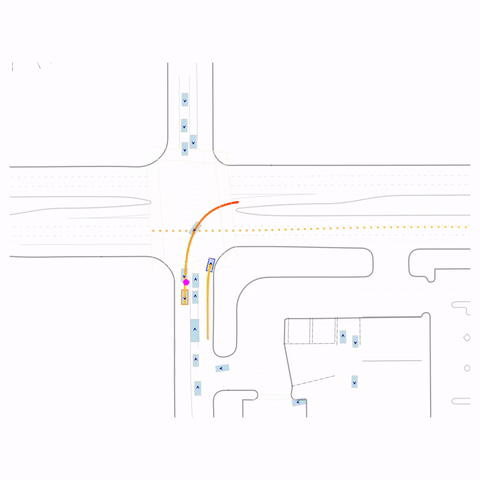
Successful Left Turn
Figure 1 (right) — GCFT Visualization. The goal point is shown with a magenta circle. We show results for concatenation (cat) and edge-indication (ind) goal representations with hard goal targets. The pre-trained model fails at the left turn, while both GCFT variants succeed.
Goal-conditioning also distills compliance with traffic rules and fine-grained parking maneuvers from a single pre-trained simulator.
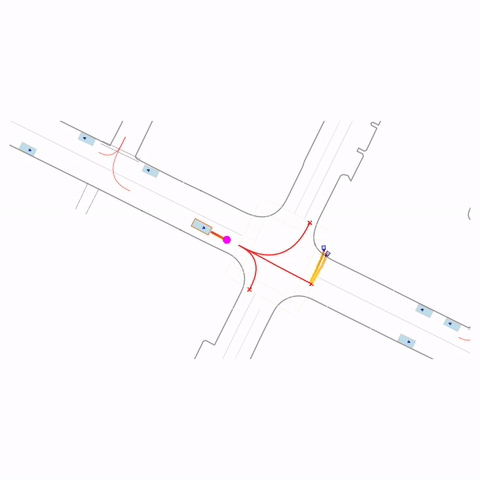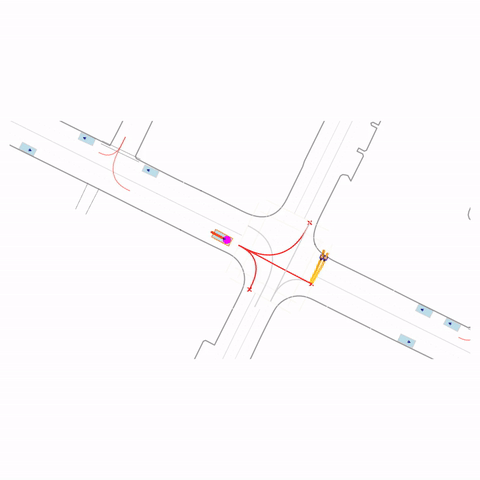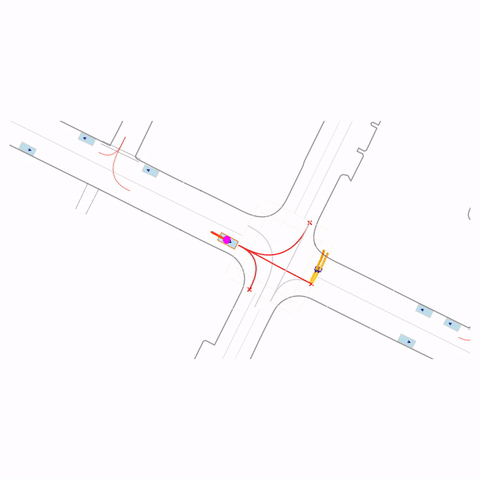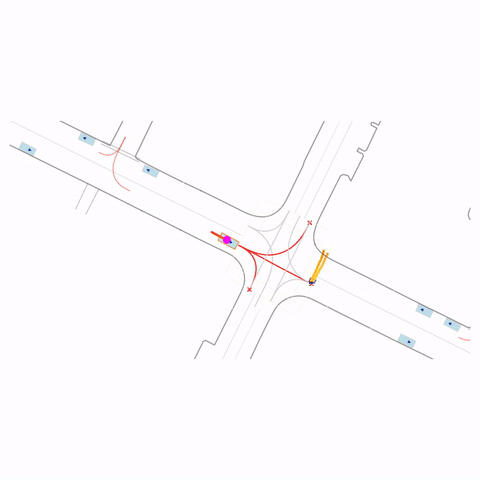
Stop at Red Light
Right Turn at Red
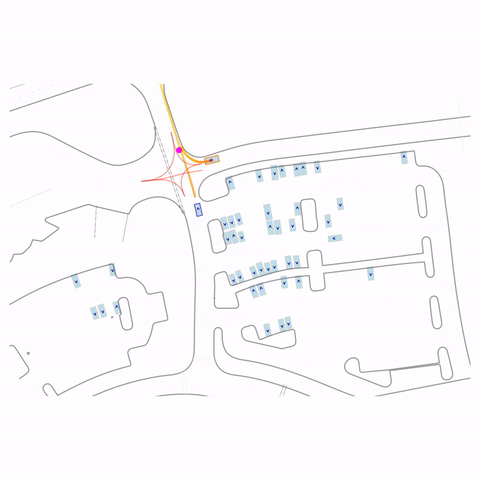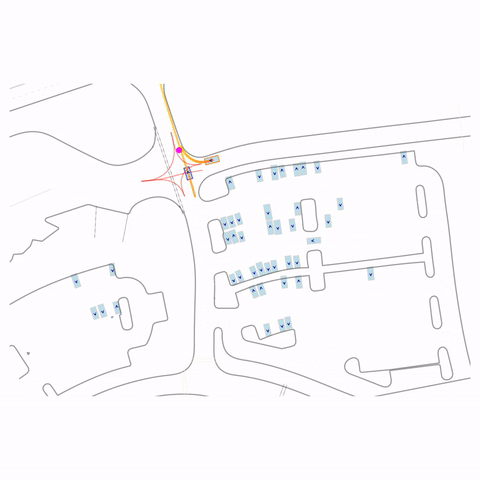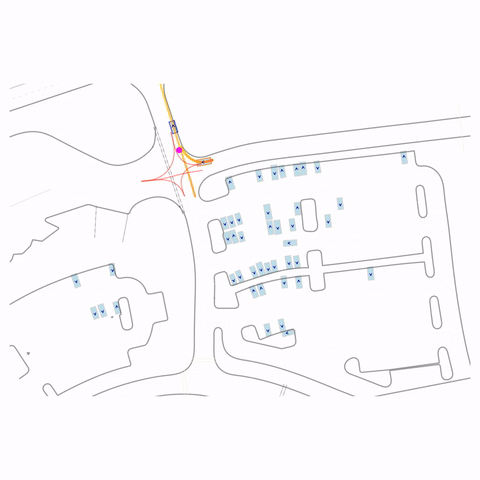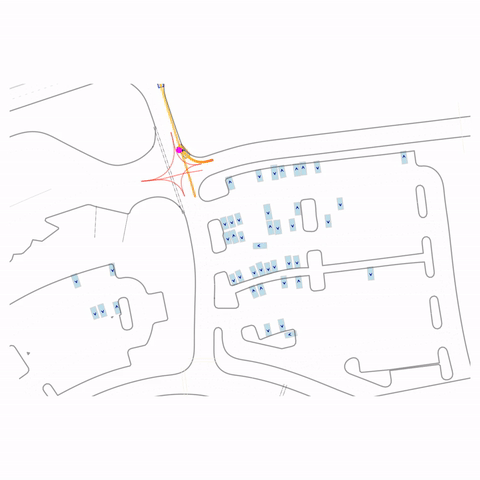
Right Turn at Stop Sign
Left Turn at Stop Sign
Move Forward
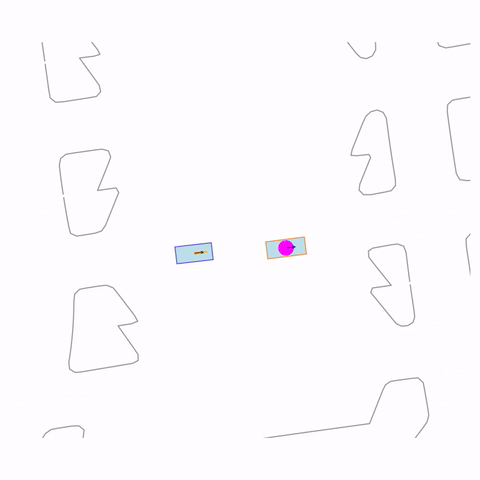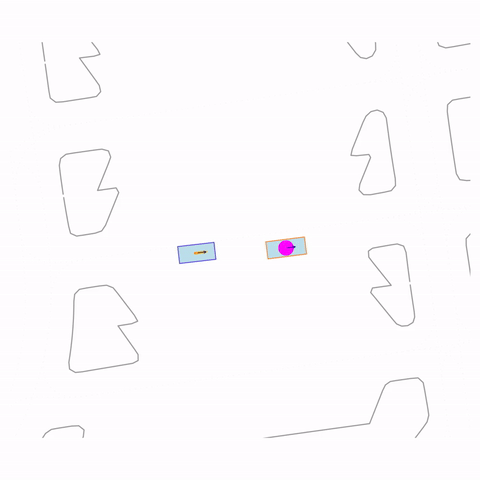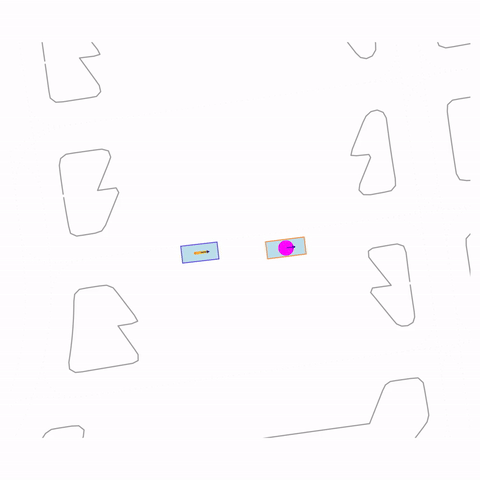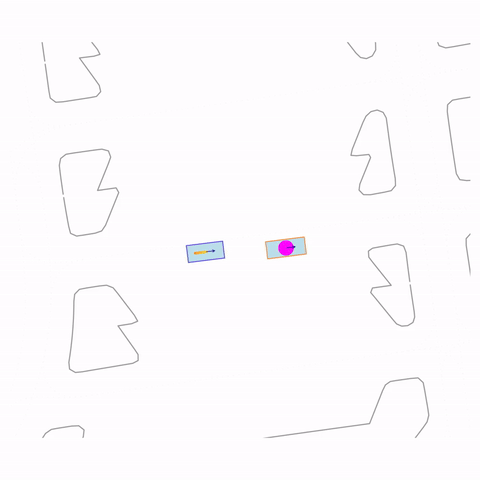
Stationary
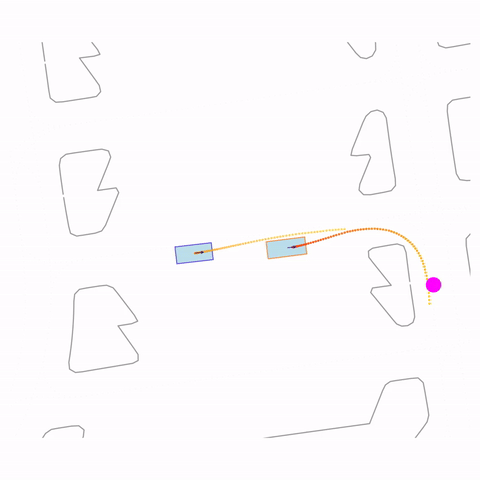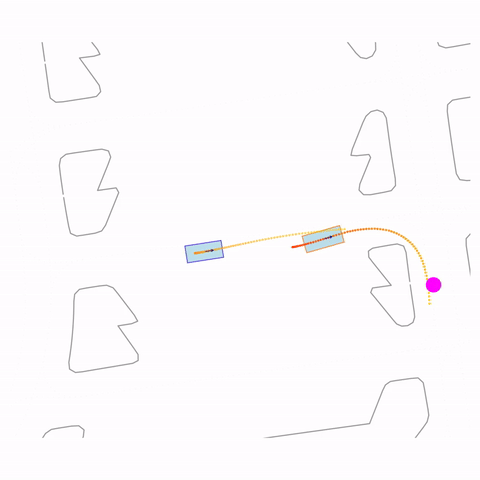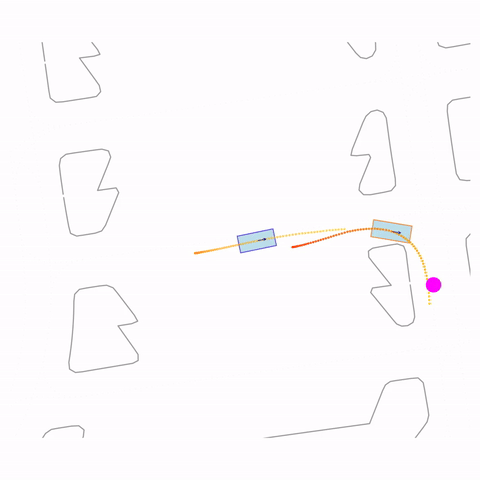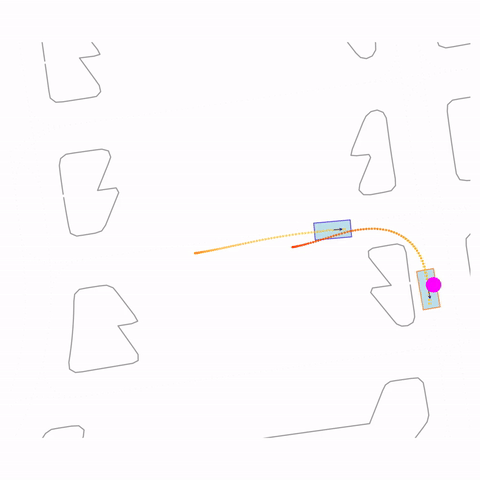
Right Turn 1
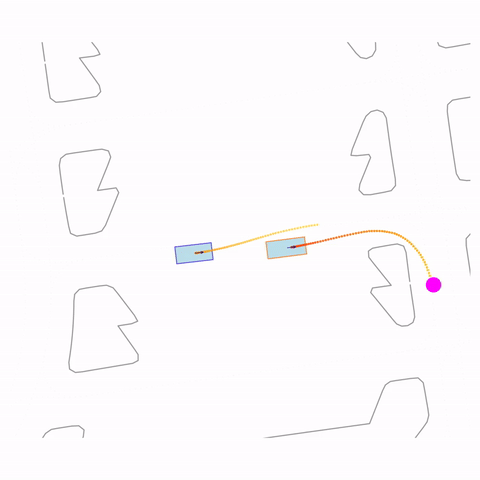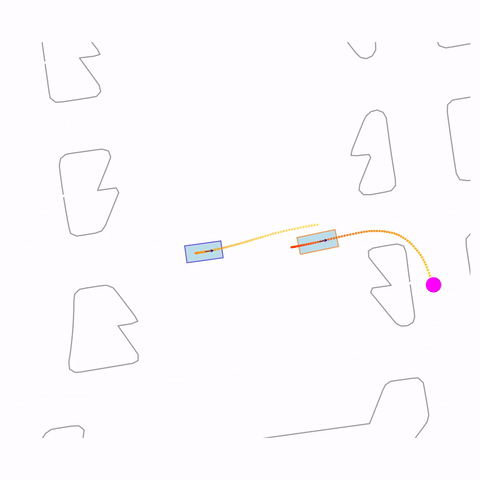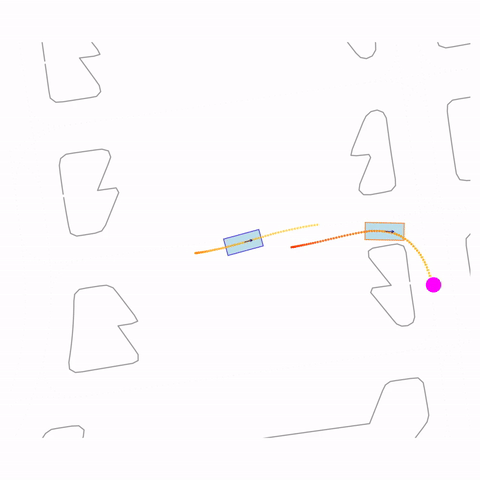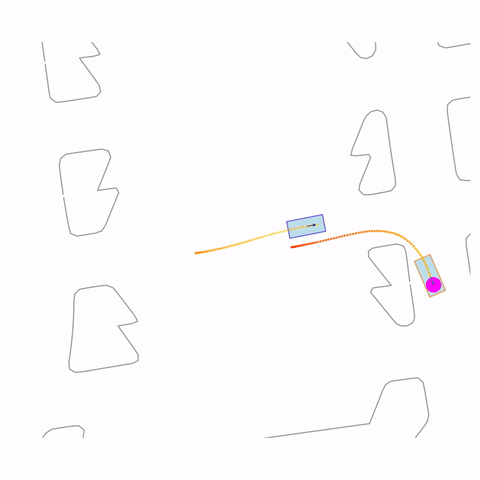
Right Turn 2
We are happy to share the RLFTSim checkpoints used in our WOSAC submission. To request access, please reach out to [eahmadi at ualberta dot ca]. Due to Waymo's data usage policy, we ask that you provide a screenshot confirming your registration on the My Submissions page of the Waymo Open Dataset. Our checkpoints are built on top of the SMART-tiny architecture. For inference, you can use the codebases from CAT-K or SMART.
@InProceedings{Ahmadi_2026_CVPR,
author = {Ahmadi, Ehsan and Schofield, Hunter and Khamidehi, Behzad and Arasteh, Fazel and Shan, Jinjun and Mou, Lili and Bai, Dongfeng and Rezaee, Kasra},
title = {RLFTSim: Realistic and Controllable Multi-Agent Traffic Simulation via Reinforcement Learning Fine-Tuning},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2026},
pages = {39734-39743},
}